이번 시리즈에서는 몽고 DB 자격증 준비를 하며 풀었던 연습문제를 정리합니다.
시험보기 직전 각 챕터별 문제를 빠르게 복기하기위한 자료입니다.
개발자를 위한 몽고 DB 자격증 로드맵 및 강의 링크는 아래와 같습니다.
MongoDB Developer Certification | MongoDB University
As a MongoDB Certified Professional, you will receive a license number, a PDF copy of your certification and a digital badge that verifies your certification. Display this badge proudly on your résumé, LinkedIn profile, email signature, forums, etc.
university.mongodb.com
$match
// $match all celestial bodies, not equal to Star
db.solarSystem.aggregate([{
"$match": { "type": { "$ne": "Star" } }
}]).pretty()
// same query using find command
db.solarSystem.find({ "type": { "$ne": "Star" } }).pretty();
// count the number of matching documents
db.solarSystem.count();
// using $count
db.solarSystem.aggregate([{
"$match": { "type": { "$ne": "Star"} }
}, {
"$count": "planets"
}]);
// matching on value, and removing ``_id`` from projected document
db.solarSystem.find({"name": "Earth"}, {"_id": 0});
Quiz : Which of the following is true about pipelines and the Aggregation Framework?

Quiz : Which of the following statements is true?

Quiz : Which of the following is/are true of the $match stage?

Homework : Help MongoDB pick a movie our next movie night! Based on employee polling, we've decided that potential movies must meet the following criteria.
- imdb.rating is at least 7
- genres does not contain "Crime" or "Horror"
- rated is either "PG" or "G"
- languages contains "English" and "Japanese"
Assign the aggregation to a variable named pipeline, like:
var pipeline = [ { $match: { ... } } ]
- As a hint, your aggregation should return 23 documents. You can verify this by typing db.movies.aggregate(pipeline).itcount()
- Download the m121/chapter1.zip handout with this lab. Unzip the downloaded folder and copy its contents to the m121 directory.
- Load validateLab1.js into mongo shell
load('validateLab1.js')
- And run the validateLab1 validation method
validateLab1(pipeline)
What is the answer?
var pipeline = [{"$match": {"imdb.rating" : {"$gte" : 7}}},{"$match": {"$nor": [{"genres": "Crime"},{"genres": "Horror"}]}},{"$match": {"$or" : [{"rated": "PG"},{"rated":"G"}]}},{"$match": {"languages":{"$all": ["English", "Japanese"]}}}]
$project
// project ``name`` and remove ``_id``
db.solarSystem.aggregate([{ "$project": { "_id": 0, "name": 1 } }]);
// project ``name`` and ``gravity`` fields, including default ``_id``
db.solarSystem.aggregate([{ "$project": { "name": 1, "gravity": 1 } }]);
// using dot-notation to express the projection fields
db.solarSystem.aggregate([{ "$project": { "_id": 0, "name": 1, "gravity.value": 1 } }]);
// reassing ``gravity`` field with value from ``gravity.value`` embeded field
db.solarSystem.aggregate([{"$project": { "_id": 0, "name": 1, "gravity": "$gravity.value" }}]);
// creating a document new field ``surfaceGravity``
db.solarSystem.aggregate([{"$project": { "_id": 0, "name": 1, "surfaceGravity": "$gravity.value" }}]);
// creating a new field ``myWeight`` using expressions
db.solarSystem.aggregate([{"$project": { "_id": 0, "name": 1, "myWeight": { "$multiply": [ { "$divide": [ "$gravity.value", 9.8 ] }, 86 ] } }}]);
Quiz : Which of the following statements are true of the $project stage?

Problem :
Our first movie night was a success. Unfortunately, our ISP called to let us know we're close to our bandwidth quota, but we need another movie recommendation!
Using the same $match stage from the previous lab, add a $project stage to only display the the title and film rating (title and rated fields).
- Assign the results to a variable called pipeline.
var pipeline = [{ $match: {. . .} }, { $project: { . . . } }]
- Load validateLab2.js which was included in the same handout as validateLab1.js and execute validateLab2(pipeline)?
load('./validateLab2.js')
- And run the validateLab2 validation method
validateLab2(pipeline)
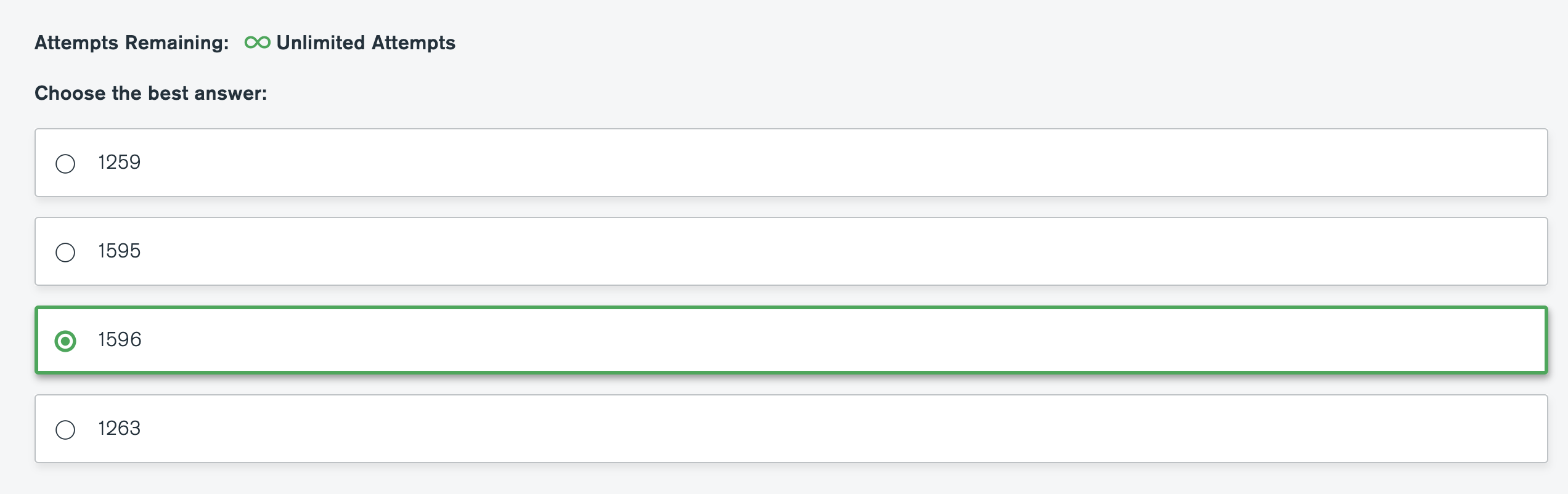
What is the answer?
var pipeline = [{"$match": {"imdb.rating" : {"$gte" : 7}}},{"$match": {"$nor": [{"genres": "Crime"},{"genres": "Horror"}]}},{"$match": {"$or" : [{"rated": "PG"},{"rated":"G"}]}},{"$match": {"languages":{"$all": ["English", "Japanese"]}}},{"$project": {"title":1, "rated": 1, "_id":0}}]
Problem :
Our movies dataset has a lot of different documents, some with more convoluted titles than others. If we'd like to analyze our collection to find movie titles that are composed of only one word, we could fetch all the movies in the dataset and do some processing in a client application, but the Aggregation Framework allows us to do this on the server!
Using the Aggregation Framework, find a count of the number of movies that have a title composed of one word. To clarify, "Cinderella" and "3-25" should count, where as "Cast Away" would not.
Make sure you look into the $split String expression and the $size Array expression
$split
{ $split: [ "June-15-2013", "-" ] }$size
db.collection.find( { field: { $size: 2 } } );To get the count, you can append itcount() to the end of your pipeline
db.movies.aggregate([...]).itcount()
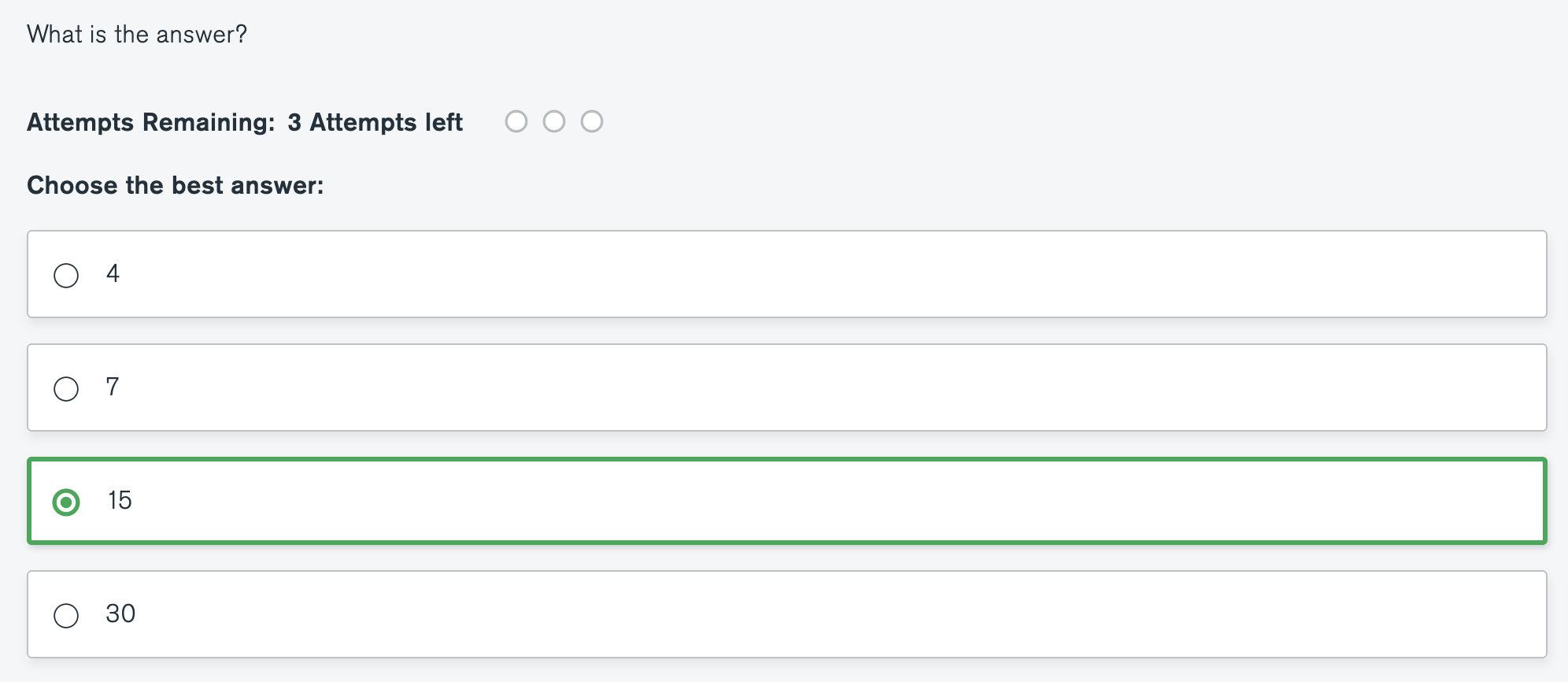
What is the answer?
db.movies.aggregate([{"$project":{"titleArray" : {"$split": ["$title", " "]}}},{"$match": {"titleArray" : {"$size":1}}}]).itcount()

Optional Lab :
This lab will have you work with data within arrays, a common operation.
Specifically, one of the arrays you'll work with is writers, from the movies collection.
There are times when we want to make sure that the field is an array, and that it is not empty. We can do this within $match
{ $match: { writers: { $elemMatch: { $exists: true } } }Within $map, the argument to input can be any expression as long as it resolves to an array. The argument to as is the name of the variable we want to use to refer to each element of the array when performing whatever logic we want. The field as is optional, and if omitted each element must be referred to as $$this:: The argument to in is the expression that is applied to each element of the input array, referenced with the variable name specified in as, and prepending two dollar signs:
writers: {
$map: {
input: "$writers",
as: "writer",
in: "$$writer"
}
}writers: {
$map: {
input: "$writers",
as: "writer",
in: {
$arrayElemAt: [
{
$split: [ "$$writer", " (" ]
},
0
]
}
}
}Problem:
Let's find how many movies in our movies collection are a "labor of love", where the same person appears in cast, directors, and writers
Hint: You will need to use $setIntersection operator in the aggregation pipeline to find out the result.
Note that your dataset may have duplicate entries for some films. You do not need to count the duplicate entries.
To get a count after you have defined your pipeline, there are two simple methods.
// add the $count stage to the end of your pipeline
// you will learn about this stage shortly!
db.movies.aggregate([
{$stage1},
{$stage2},
{...$stageN},
{ $count: "labors of love" }
])
// or use itcount()
db.movies.aggregate([
{$stage1},
{$stage2},
{...$stageN}
]).itcount()$setIntersection
Takes two or more arrays and returns an array that contains the elements that appear in every input array.
db.experiments.aggregate(
[
{ $project: { A: 1, B: 1, commonToBoth: { $setIntersection: [ "$A", "$B" ] }, _id: 0 } }
]
)db.movies.aggregate([
{
$match: {
cast: { $elemMatch: { $exists: true } },
directors: { $elemMatch: { $exists: true } },
writers: { $elemMatch: { $exists: true } }
}
},
{
$project: {
_id: 0,
cast: 1,
directors: 1,
writers: {
$map: {
input: "$writers",
as: "writer",
in: {
$arrayElemAt: [
{
$split: ["$$writer", " ("]
},
0
]
}
}
}
}
},
{
$project: {
labor_of_love: {
$gt: [
{ $size: { $setIntersection: ["$cast", "$directors", "$writers"] } },
0
]
}
}
},
{
$match: { labor_of_love: true }
},
{
$count: "labors of love"
}
])